DML :
Data Manipulation Language
RDBMS 테이블 데이터를 저장, 수정, 삭제하는 명령어
| INSERT | SELECT | UPDATE | DELETE |
# SELECT 문
데이터베이스에서 정보를 검색하는데 사용되는 코드
순서)
SELECT DISTINCT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
1. SELECT절 :
SELECT 문의 시작을 담당
어떤 열을 반환할건지 지정함
SELECT * : 모든 열을 의미
SELECT column1, column2, column3, ... columnN;
>> 해당 column들이 반환하고자하는 테이블 열의 이름이다!
# DISTINCT 키워드
중복된 결과를 제거하고 고유한(unique) 결과만을 반환하는데 사용
SELECT절에서 column 앞에 작성한다
SELECT DISTINCT column1, column2, column3, ... columnN
2. FROM절 :
어떤 테이블에서 데이터를 검색할 것인지 지정
마지막을 담당
FROM table
>> 해당 table 내에서 데이터를 검색하고자 한다!
ex 1 )
SELECT *
FROM table1, table2, table3;
>> 이렇게 하면 오류남
ex 2 )
SELECT table1.column1, table2.column2
FROM table1, table2;
>> 테이블은 객체니까 이렇게 해야함
ex 3 )
SELECT t1.column1, t2.column2
FROM table1 t1, table2 t2;
3. ORDER BY절
정렬 순서 지정
특정 열 또는 여러 열에 따라 정렬해줌
기본적으로 오름차순(ASC)
내림차순(DESC)을 사용하려면 DESC 키워드를 사용해아함
SELECT column1, column2, column3, ... columnN
FROM table
ORDER BY column1 ASC, column2 DESC, ... columnN ASC;
>> 순서대로 정렬, column1 기준정렬, column2 기준정렬 ...
동일한 앞의 값에 대해 뒤의 조건으로 정렬하는 것
4. WHERE절
특정 조건을 만족하는 row(행)를 선택하도록 필터링 해주는 친구
필터링이라 조건식이 필요하고, 만족하는 행 만이 결과에 포함된다
SELECT column1, column2, column3, ... columnN
FROM table
ORDER BY condition;
SELECT *
FROM table
WHERE age > 30 AND age < 50;
@ 연산자
비교연산자 :
< , > , <= , >= , = , != , NOT, AND, OR
BETWEEN ... AND ... :
특정 범위 내에 있는 값 선택
WHERE a BETWEEN 1 AND 100
>> 1 < a < 100 이거 안됨
IN :
WHERE a IN ("개발부서", "디자인부서", "영업부서")
Like :
문자열 패턴 매칭을 위해 %와 함께 사용
% : 임의의 문자열을 대체
_ : 임의의 문자 한개를 대체
WHERE name LIKE '_A%' : 이름의 두번째 글자가 A인 친구들만 가져와줘
WHERE job LIKE '%A%' : 직업에 A가 들어간 모든 친구들 가져와줘
IS NULL, IS NOT NULL :
NULL인지 아닌지 판단해줌
5. GROUP BY절
특정 열에 따라 그룹화 하는 친구
보통 집계함수와 함께 사용되어 결과집합을 그룹화해주거나 계산해주는데 사용되는 친구
SELECT column1, column2, column3, ... function(columnN)
FROM table
GROUP BY column1, column2
>> column1 column2 해당 열에서 columnN열을 function으로 계산함
ex)
SELECT id, ... AVG(salary)
FROM table
GROUP BY id, name;
>> 테이블에서 각 id, name의 평균 급여(salary)를 계산하는 쿼리
6. HAVING절
GROUP BY의 친구라서 같이 써야함
GROUP BY에서 추가 필터링을 도와줌
GROUP화가 된 전체 객체에 대한 조건을 지정해줌
SELECT column1, column2, column3, ... function(columnN)
FROM table
GROUP BY column1, column2
HAVING condition;
# 연산기법
1. 셀렉션 Selection
특정 조건을 만족하는 행을 선택하는 연산
SQL에서는 WHERE절을 사용해서 셀렉션을 한다.
2. 프로젝션 Projection
특정 열만 선택하는 연산
SELECT column1, column2, ... << 이거
3. 조인 Join
여러 개의 테이블에서 관련있는 데이터를 결합하는 연산
두개 이상의 테이블을 열 기준으로 결합해주는 SQL 연산
공통된 열을 기준으로 작업
JOIN ... ON ...
ON: 뒤에 서로 연관있는 연산이 나옴
SELECT emp.first_name, emp.last_name. dept.deptname
FROM emp
JOIN dept ON emp.id = dept.id
>> emp.id와 dept.id가 같은 친구들만 쪼인하겠다 라는 뜻
☞ oracle join
- JOIN 앞에 붙임
- 모두다 일치하지 않는 경우는 NULL 반환
1. INNER JOIN
두 테이블에서 일치하는 행만 반환
2. LEFT OUTER JOIN
첫번째 테이블의 모든 행 그리고 두번째 테이블과 일치하는 행을 반환
3. RIGHT OUTER JOIN
두번째 테이블의 모든 행 그리고 첫번째 테이블과 일치하는 행을 반환
4. FULL OUTER JOIN
두개의 모든 데이터를 가져와서 한쌍으로 만들고 전체 데이터를 반환
5. CROSS JOIN
첫번째 테이블과 두번째 테이블의 모든 조합을 반환 << 셀렉*하고두개출력하는거랑똑같
6. SELF-JOIN
자기 자신의 여러 ROW간의 JOIN 연산 수행
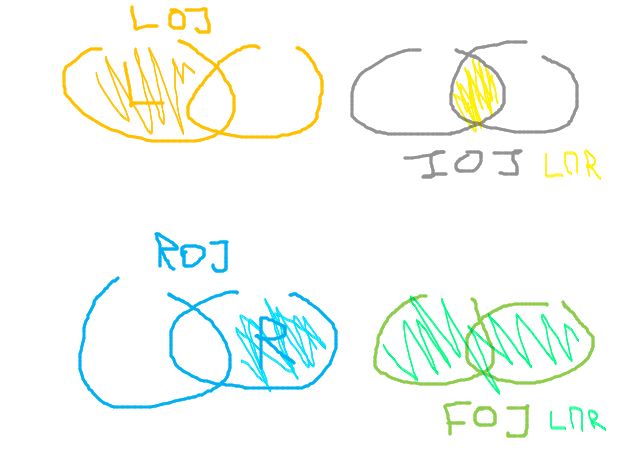
L ∪ R
FROM L
FULL OUTER JOIN R
L - L ∩ R
FROM L
LEFT OUTER JOIN R ON L.VALUE = R.VALUE
WHERE R.VALUE IS NULL
R - L ∩ R
FROM R
LEFT OUTER JOIN L ON L.VALUE = R.VALUE
WHERE L.VALUE IS NULL
L ∪ R - L ∩ R
FROM L
FULL OUTER JOIN R ON L.VALUE = R.VALUE
WHERE L.VALUE IS NULL OR R.VALUE IS NULL
☞ SQL-99 join
1. NATURAL JOIN
두개 이상의 동일한 이름을 가진 열들 사이에서 자동으로 일치하는 열들을 결합
ON 사용 안함
SELEC절에서 JOIN의 기준이 되는 column 의 이름을 명시할때 객체 이름을 붙이면 안됨
>> 식별자를 가질 수 없는 오류가 있을 수 있음
SELECT *
FROM EMP E1
NATURAL JOIN EMP E2;
SELECT E.EMPNO, E.ENAME, E.MGR, DEPTNO, D.DNAME, D.LOC
FROM EMP E
NATURAL JOIN DEPT D;
>> DEPTNO 기준으로 합쳐지기 때문에 DEPTNO는 테이블이 뭔지 명시할 필요 없음
2. USING 절
두개 이상의 동일한 이름을 가진 열들 사이에서 자동으로 일치하는 열들을 결합
SELECT E.EMPNO, E.ENAME, E.MGR, DEPTNO, D.DNAME, D.LOC
FROM EMP E
JOIN DEPT D USING(DEPTNO);
3. ON 절
조건식(비교 연산자)들과 결합할 열들을 직접 비교할 수 있음
4. NVL (NULL VALUE)
☞ 뒤에서 다시 다룸
널값이면 계산이 이상해짐
NVL(값, 대체값)
SELECT SAL*12+ NVL(COMM, 0) AS TOTAL_SAL
FROM EMP;
>> COMM중에 NULL 값 있으면 0으로 대체해서 계산해줘
# 집합연산자
1. UNION
두개의 SELECT문 결과를 중복된 행 제거 후 결합
조건: SELECT문에서 동일한 수의 열을 가져야하고, 유사한 데이터 타입을 가져야 함
ex) 불가능 ↓
1 1
1 1 + 3 3
1 1
SELECT column1 FROM table1
UNION
SELECT column2 FROM table2
ex)
사원번호, 이름, 직급, 급여, 부서번호 출력
(조건: 부서번호20, 급여2000이상, 부서번호30, 급여2000이상)
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO
FROM EMP
WHERE SAL >= 2000 AND DEPTNO = 20
UNION
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO
FROM EMP
WHERE SAL >= 2000 AND DEPTNO = 30;
2. UNION ALL
두개의 SELECT문 결과를 중복된 행 제거하지는 않고 결합
SELECT column1 FROM table1
UNION ALL
SELECT column2 FROM table2
3. INTERSECT
두개의 SELECT문 결과 중 공통된 행만 반환
SELECT column1 FROM table1
INTERSECT
SELECT column2 FROM table2
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO
FROM EMP
WHERE DEPTNO = 30
INTERSECT
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO
FROM EMP
WHERE JOB = 'SALESMAN';
4. EXCEPT(MINUS)
첫번째 SELECT문 결과에서 두번째 SELECT문의 결과에 있는 행들 제외하고 나머지만 반환
SELECT column1 FROM table1
EXCEPT
SELECT column2 FROM table2
SELECT column1 FROM table1
MINUS
SELECT column2 FROM table2

# CASE문
DECODE 와 비슷
조건에 따라 다른 동작을 수행하거나 반환하는 역할 수행
WHEN 조건 THEN 결과
조건이 T면 THEN에 있는 결과 반환
SELECT ENAME,
CASE
WHEN DEPT = 'IT' THEN 'IT DEPARTMENT'
WHEN DEPT = 'SALES' THEN 'SALES DEPARTMENT'
ELSE 'OTHER DEPARTMENT'
END AS DEPARTMENT, SAL
FROM EMP;
# 고급 그룹화 연산 함수
그룹바이를 도와주는 친구들 (HAVING과 같은 포지션)
1. ROLLUP
GROUP BY 절에 지정된 열 목록에 대해
서브그룹(소그룹), 각 열에 대한 합계 생성
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY (DEPTNO, JOB);
>> DEPTNO와 JOB 기준으로 겹치지 않게(고유하게) 합계 생성
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);
>> DEPTNO와 JOB 기준 합계 뿐 아니라 나머지 그룹의 합계까지 생성
>> DEPTNO각각합계, JOB각각합계, DEPTNO 전체 합계, 전체그룹과의 최종합계
2. CUBE
GROUP BY 절에 지정된 열 목록에 대해
서브그룹(소그룹), 각 열에 대한 합계 생성
다차원 분석 쿼리에 유리
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB);
>> 쪼갤수있는거 다 쪼개서 계산해줌
3. GROUPING SETS
GROUP BY 절에 지정된 열 목록에 대해
서브그룹(소그룹), 각 열에 대한 합계 생성
복잡한 그룹화에서 사용
SELECT DEPTNO, JOB, SUM(SAL)
FROM EMP
GROUP BY GROUPING SETS((DEPTNO), (JOB));
>> 쪼갤수있는거 다 쪼개서 계산해줌
# GROUPING
# 그룹바이 함수를 도와주는 친구들을 도와주는 친구
직접적으로 합계를 생성해주는 함수는 아니고
그룹함수들을 도와주는 함수
CASE, DECODE와 절친
집계된 결과에서는 1, 안된 결과에서는 0 의 값을 가짐
조건문에도 활용할 수 있음
SELECT DEPTNO, JOB, COUNT(*), SUM(SAL), GROUPING(DEPTNO), GROUPING(JOB)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB);
'DataBase' 카테고리의 다른 글
| [DataBase] Subquery 서브쿼리 하위질의 (0) | 2023.08.31 |
|---|---|
| [OracleDB] SCOTT 계정 실습문제 (0) | 2023.08.29 |
| [OracleDB] Toad 설치 (0) | 2023.08.29 |
| [DataBase] SQL (종류, 키, 자료형) (0) | 2023.08.29 |
| [DataBase] Intro (0) | 2023.08.29 |
